Notes take
Prev: 8-route-53 \
Refresher
Relational (SQL) vs Non-relational (NoSQL)
- Difference in structure in and between tables of data. Relational is fixed.
- NoSQL is anything that is different. Generally more relaxed schema.
Relational data:
- has primary key that is unique value
- JOIN based on primary key
- Composite key - unique key based on multiple columns
Database type:
- Key-Value
- No schema, No structure
- Scalable
- Really fast
- Wide Column Store
- Table has partition key that is fixed structure
- Item in other tables has no attribute schema (any/ all/ none)
- Document
- Usually formatted as JSON, XML
- Extension of Key-Value store
- Ideal for interacting with whole docs or deep attribute interactions
- Column
- Row Store (MySQL)
- See each row has order id, product, colour, size
- Ideal for operating CRUD with rows - Online Transaction Processing
- Column Store (Redshift)
- See each item grouped based on columns
- Ideal for reporting when all or specific attribute required
- Row Store (MySQL)
- Graph
- Has nodes (subject) and edges (relationship)
- Good for social medias
ACID vs BASE
ACID and BASE are DB transaction models
CAP Theorem - Consistency, Availability, Partition Tolerant (Resilient)
- Can only choose 2
- ACID focus Consistency
- BASE focus Availability
ACID - Atomic Consistent Isolated Durable
- RDS, limits scaling
- Atomic - all or no component of transaction succeeds or fails
- Consistent - transaction move database from a valid state to another, nothing in-between
- Isolated - If multiple transaction occurs at once, they do not interfere and executed as only one
- Durable - Once committed, transactions are durable. Stored on non-volatile memory that is resilient
ACID fact:
- Used by most, esp financial firms where consistent is important
- Rigid rules limit scaling
BASE - Basically Available, Soft state, Eventually consistent
- BA - Read and Write Operations are available as much as possible without any consistency guarantees. Available ^ Consistency V
- S - Database does not enforce consistency, offloaded onto application or user
- E - If waited long enough, reads from system will be consistent
Base Fact:
- Highly scalable and performant
- BASE → NoSQL
- ACID → defaults to SQL
- NoSQL + ACID → DynamoDB
Databases on EC2
Types:
- EC2 Instance - Web, App, Database
- 2 EC2 Instance, 1 for Web, App and 1 for Database
Why database on EC2:
- Access to DB Instanc e OS
- Advanced DB Option tuning (DBROOT)
- Vendor demand
- Database or its version that AWS do not provide
- Architecture AWS do not provide (replication, resilience)
Why not:
- Admin overhead - Managing EC2 and DBHost
- Backup/ Disaster Recovery management
- EC2 is only AZ resilient
- Features - Some of AWS DB prods are good
- EC2 is ON or OFF - no serverless, no easy scaling
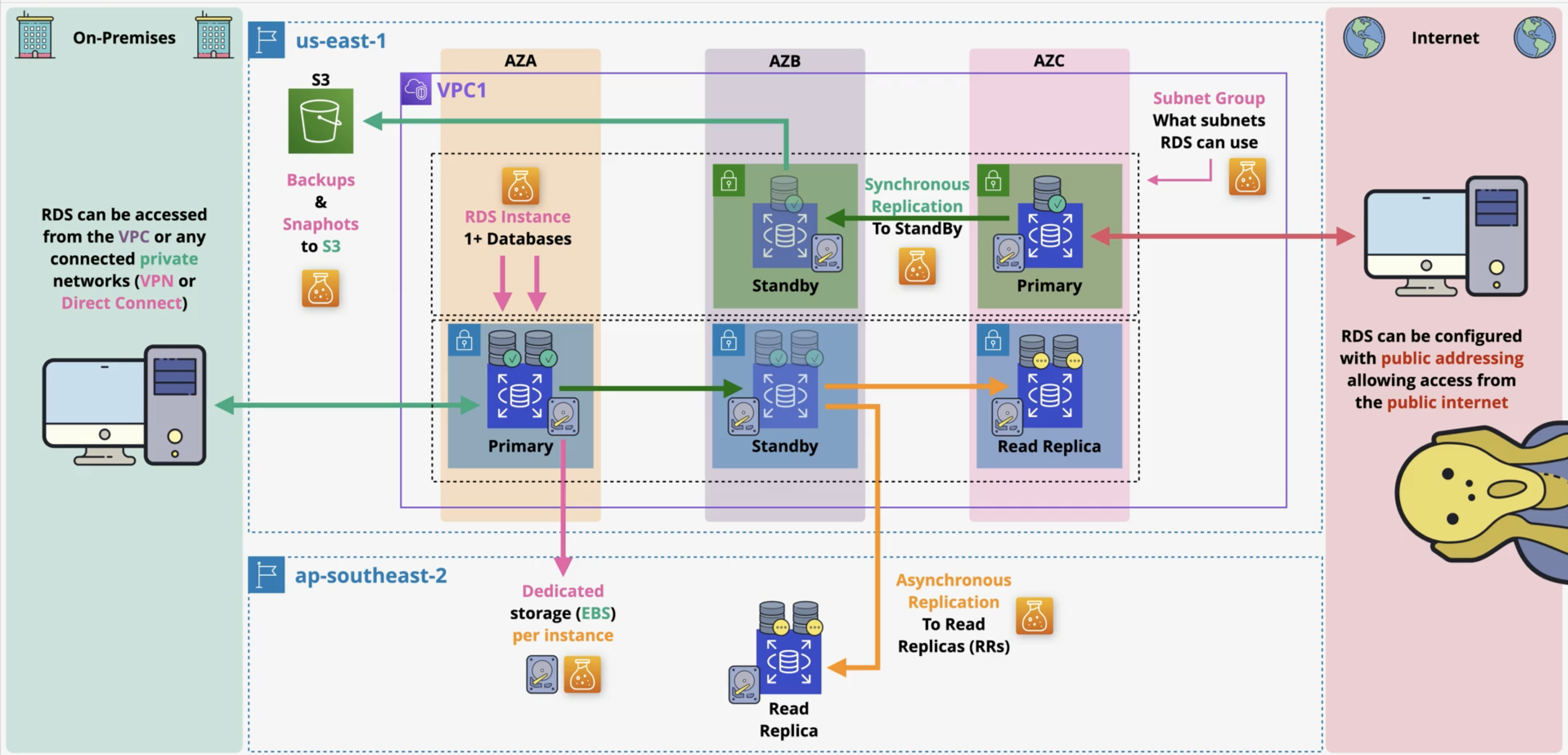
Relational Database Service Architecture
RDS Architecture:
- Database Server as a Service (DBSaaS)
- Pay and receive database server
- Not a DBaaS
- Can have multiple dbs on 1 server
- Choice of DB Engines (MySQL, MariaDB, PostgreSQL, Oracle, MS SQL Server)
- Not Amazon Aurora - custom DB engine with compatibility with above engines
- Managed services - no access to OS or SSH
RDS Costs:
- Instance size and type
- Multi AZ or not
- Storage type and amount
- Data transferred
- Backups and Snapshots
- Licensing
To create RDS in AWS, need subnet group - to inform RDS which subnet within VPC for DB instance
# Backup of Source Database
mysqldump -h PRIVATEIPOFMARIADBINSTANCE -u a4lwordpress -p a4lwordpress > a4lwordpress.sql
# Restore to Destination Database
mysql -h CNAMEOFRDSINSTANCE -u a4lwordpress -p a4lwordpress < a4lwordpress.sql
# Change WP Config
cd /var/www/html
sudo nano wp-config.php
replace
/** MySQL hostname */
define('DB_HOST', 'PRIVATEIPOFMARIADBINSTANCE');
with
/** MySQL hostname */
define('DB_HOST', 'REPLACEME_WITH_RDSINSTANCEENDPOINTADDRESS');
RDS MultiAZ
MultiAZ Architecture:
- Access primary DB through DB CNAME unless failover
- Synchronous replication to standby to other dbs that will replicate to other S3
- Can take 1-2 mins when DB CNAME changed to point to Standby
- Data ⇒ Primary AND replicated to standby = Committed (Synchronouse)
- Extra cost for replication
- 1 StandBY replica only that can be used for RW
- 1-2 mins failover
- Only same region, different AZ
- Backups taken from standby to improve performance
MultiAZ Cluster Mode vs Amazon Aurora:
- MultiAZ Cluster
- 1 Primary with RW that is synchronized to other DBs
- Non-primary readonly
- Accessed through few endpoints
- Cluster endpoint for write - R, W, Admin
- Reader endpoint - R
- Instance endpoint for specific instance - testing/ fault finding
- 1 Writer and 2 Reader DB instances (different AZs)
- Much faster hardware, Graviton + local NVME SSD storage
- Fast write to local storage ⇒ EBS
- Reader only for read for scale
- Replication via transaction logs - more efficient
- Failover only 35s + transaction log
- Writes committed when 1 reader has confirmed
RDS Automatic Backup, Snapshots, and Restore
Within RDS, 2 type of backups (both to S3):
- Automated backups - once per day
- If single AZ, make sure to run on quite times
- Multi AZ fine because backup from standby
- If single AZ, make sure to run on quite times
- Snapshots
AWS Managed S3 Buckets - Globally resilient
- First snap is Full size of consumed data
- Onwards are incremental
- Every 5 minute transaction logs
- Retention period is 0 to 35 days
- Restore using snapshots and transaction logs
RDS Cross-region backups:
- RDS can replicate backups to another region
- Both snapshots and transaction logs
- Charges apply for cross-region data copy and storage and dest region
- Not default - configured with auto backups
RDS restores:
- Create new RDS instance with new address
- Snapshots = single point in time, creation time
- Automated - any 5 minute point in time
- Ensure good RPO (not failure)
- Backup restored and transaction logs replayed to bring DB to desired point in time
- Resote are not fast - think about RTO/ RR’s
RDS Read-Replicas
AWS Read Replicas - Read only DB replicas
Read-replicas stats:
- Asynchronous replication to RRs
- Can be created in same/ different regions
Benefits:
- Performance benefits for read
- 5x direct read-replicas per DB instance
- Each providing additional instance of read performance
- Read-replicas can have read-replicas
- Lag can be problem though
- Global performance improvements
- Cross-region failover capability
- RDS to meet really low RTOs (Recovery Time Objectives) - RPO/ RTO Improvement
- Snapshots and backups improve RPO
- RTO’s are a problem
- Read replicas offer near 0 RPO
- Read replicas can be promoted quickly - low RTO
- Only for failure - watch for data corruption
- Readonly until promoted
- Global availability improvements - resilience
RPO (Recovery Point objective) - max data loss application can tolerate
RTO (Recovery Time Objective) - how quickly time for app to recover after outage
RDS Data Security
Things to focus:
- Authentication - How to log in
- Authorization - How access is controlled
- Encryption in transit - Client — RDS
- Encryption in rest - Data when written to disk
Security:
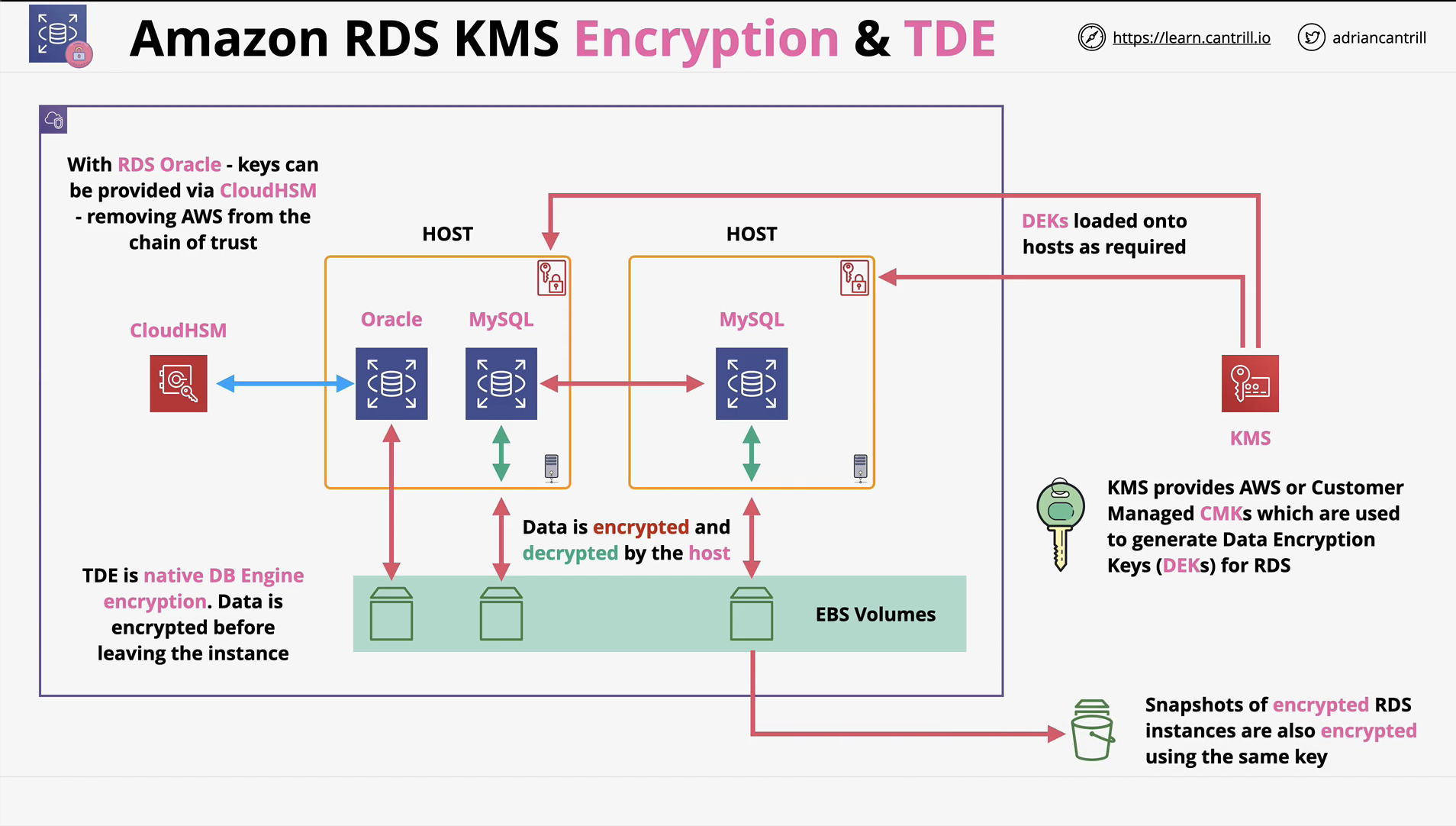
- SSL/ TLS (in transit) available for RDS - can be mandatory
- RDS supports EBS volume encryption by KMS
- Handled by Host/ EBS
- AWS or Customer-managed CMK generates data key
- Data keys for encryption ops
- Storage, logs, snapshots, replicas are encrypted and cannot be removed
Support Integration:
- RDS MSSQL and Oracle support Transparent Data Encryption (TDE)
- Encryption handled within DB engine
- RDS Oracle supports integration with CloudHSM
- Much stonger key controls (even from AWS)
Amazon RDS KMS Encryption and TDE:
Amazon RDS IAM Authentication:
- RDS local DB account use AWS auth token
- generate-db-auth-token to create token within 15 mins validity in place of DB user password - from IAM
- Only authentication, authorisation still by DB engine
RDS Custom
RDS Custom - fills the gap between main RDS and EC2 running DB engine
- RDS is fully managed - Limited OS/ engine access
- DB on EC2 is self managed - Has overhead
- Currently works for MS SQL and Oracle
- Can connect using SSH, RDP, Session Manager
- RDS Custom DB Automation
- Pause to customize (no disruptions)
- Resume for normal production usage
Amazon Aurora
Aurora - Part of RDS, but architecture is very different
- Uses a “Cluster” - improve both availability and read operation
- Single primary instance - 0+ replicas
- No local storage - uses shared cluster volume
- Max 128 TiB, 6 Replicas, AZs
- Faster provisioning, improved availability and performance
- Chances of losing data from disk almost 0
- When part of disk fails, immediately repairs from data outside other storage nodes
- Less needed to restore and snapshot
- Failover operation much faster
Aurora Storage Architecture:
- All SSD based - high IOPS, low latency
- Storage is billed based on what is used
- High water mark - billed for most used
- Changed for most recent aurora
- Storage which is freed up and can be reused
- Replicas can be added and removed without storage provisioning
- Since storage is in cluster, not in instance
Endpoints:
- Cluster endpoint for primary Read-Write
- Reader endpoint for replicas Read
- Has load balancing for scale
Cost:
- No free-tier option
- No micro-instances
- Beyond RDS singleAZ (micro), aurora offers better value
- Compute - hourly charge, per second, 10 min minimum
- Storage - GB-Month consumed, IO cost per reuqest
- 100% DB Size in backups included
Aurora restore, clone, and backtrack:
- Backups in Aurora work in same way as RDS
- Restores creates a new cluster
- Backtrack can be used for in-place rewind to previous point in time
- Fast clone - make database much faster than copying all data - copy-on-write
- References original storage and only contains the diff
Aurora Serverless
Aurora serverless - Like fargate for Aurora
- Less admin overhead, More to Database as a Service
- Scalable - ACU (Aurora Capacity Units)
- Cluster has min and max ACu and adjusts based on load
- Can go to 0 or paused
- Consumption billing per-second basis
- Same resilience as Aurora (6 copies across AZs)
- ACU can dynamically resize and will have more compute resources
- Proxy Fleet - manages connection between cluster rather than provisioned
- Managed by AWS
- Act as gateway broker to allow fluid scaling
Use cases:
- Infrequently used applications - per-second basis
- New applications - unsure of load placed
- Variable workloads - lightly used app with peaks
- Unpredictable workloads - set fairly large ACU range
- As development and test databases - can pause or resume to scale back to 0
- Multi-tenant apps - Incoming load align with revenue (scaling is aligned)
Aurora Global Database
Aurora Global database - Global level of replication using Aurora from master region to up to 5 secondary AWS regions
- Primary region - 1 RW and 15 read replicas
- Secondary region - 16 read replicas
- ~1s replication of the cluster volume
Use case:
- Cross-Region Disaster Recovery (DR) and Business Continuity (BC)
- RPO and RTO will be low
- Global read scaling - low latency perf improvements
- ~1s or less replication between regions
- No impact on DB performance
- Secondary region with 16 replicas - can be promoted to R/W
Aurora Multi-Master
Aurora Multi-Master - Aurora with multiple instances with R/W operations
- Default is Single-Master (1 R/W)
- All instances are R/W
- Cluster endpoint for write, read endpoint for load-balanced reads
- Failover takes time - replica promoted to R/W
Process:
- 1 write will commit writes into all clusters
- Change is also replicated to other nodes in other clusters for consisency
Benefits:
- More fault-tolerant than single-master if primary instance error-ed